通过把xlcoc转换为JSON让AI帮助翻译成多种语言并转换回xliff格式
本文将会以Apple 2021/2020 WWDC的示例程序 Fruta: Building a Feature-Rich App with SwiftUI 来作为用GPT4来多语言本地化的例子
由于买API比较麻烦所以本文使用的是半自动的通过粘贴JSON到ChatGPT Plus的方式进行翻译
(特别是将来GPT4 32k版推出的话应该支持绝大多数翻译的字数要求了)
你也可以修改成使用API的完全自动化流程避免手动粘贴
xlcoc转换成JSON
我们知道Xcode可以直接用LocalizedStringKeys来抽取需要翻译的文本,然后导出为各种语言的xlcoc文件,而这个文件夹本身是包含xliff的,所以我们可以用xml的相关支持来读取修改
于是编写了一段Python代码来让Xcode导出的翻译文件夹生成一个适用于类似GPT4这样的AI翻译的JSON文件
import os
import json
import xml.etree.ElementTree as ET
# 这是你的xcloc文件所在的文件夹
input_dir = "/Users/nhuji/Desktop/Fruta Localizations"
# 这是你想要将解析出的数据保存为JSON的文件夹
output_dir = "/Users/nhuji/Desktop/Fruta Localizations JSON"
# 创建一个字典来保存所有的数据
data = {}
# 遍历文件夹中的所有文件
for filename in os.listdir(input_dir):
# 检查文件是否是xcloc文件
if filename.endswith(".xcloc"):
# 获取语言代码
language_code = filename[:-6] # 去掉".xcloc"后缀
# 找到xcloc文件中的xliff文件
for root, dirs, files in os.walk(os.path.join(input_dir, filename)):
for file in files:
if file.endswith(".xliff"):
# 解析xliff文件
tree = ET.parse(os.path.join(root, file))
root = tree.getroot()
# 遍历xliff文件中的所有file元素
for file in root.iter('{urn:oasis:names:tc:xliff:document:1.2}file'):
# 获取original属性值
original = file.get('original')
# 如果这个original还没有在数据字典中,就添加一个新的条目
if original not in data:
data[original] = {}
# 遍历file元素中的所有trans-unit元素
for trans_unit in file.iter('{urn:oasis:names:tc:xliff:document:1.2}trans-unit'):
# 获取id、source、target和note元素的文本
id = trans_unit.get('id')
source = trans_unit.find(
'{urn:oasis:names:tc:xliff:document:1.2}source').text
target_element = trans_unit.find(
'{urn:oasis:names:tc:xliff:document:1.2}target')
target = target_element.text if target_element is not None else ""
note = trans_unit.find(
'{urn:oasis:names:tc:xliff:document:1.2}note').text
# 如果这个id还没有在数据字典中,就添加一个新的条目
if id not in data[original]:
data[original][id] = {
'source': source, 'note': note}
# 将这种语言的翻译添加到数据字典中
data[original][id][language_code] = target
# 将字典转换为JSON格式,并保存到文件中
os.makedirs(output_dir, exist_ok=True)
with open(os.path.join(output_dir, 'translations.json'), 'w', encoding='utf-8') as f:
json.dump(data, f, ensure_ascii=False, indent=4)
这个代码运行完毕后我们应该得到类似下面的JSON文件
{
"Shared/Resources/en.lproj/InfoPlist.strings": {
"CFBundleDisplayName": {
"source": "Fruta",
"note": "Bundle display name",
"ru": "Фрута",
"zh-Hant": "Fruta",
"en": "Fruta",
"zh-Hans": "Fruta",
"ja": "Fruta"
},
"CFBundleName": {
"source": "Fruta",
"note": "Bundle name",
"ru": "Фрута",
"zh-Hant": "Fruta",
"en": "Fruta",
"zh-Hans": "Fruta",
"ja": "Fruta"
},
"NSHumanReadableCopyright": {
"source": "Copyright © 2020-2021 Apple. All rights reserved.",
"note": "Copyright (human-readable)",
"ru": "© 2020–2021 Apple. Все права защищены.",
"zh-Hant": "Copyright © 2020-2021 Apple. All rights reserved.",
"en": "Copyright © 2020-2021 Apple. All rights reserved.",
"zh-Hans": "Copyright © 2020-2021 Apple. All rights reserved.",
"ja": "Copyright © 2020-2021 Apple. All rights reserved."
}
},
"Shared/Resources/en.lproj/Ingredients.strings": {
"Almond Milk": {
"source": "Almond Milk",
"note": "Ingredient name",
"ru": "Миндальное молоко",
"zh-Hant": "",
"en": "Almond Milk",
"zh-Hans": "",
"ja": ""
},
...
}
用AI翻译JSON
使用类似下面这样的Prompts(提示词)然后就可以发送需要翻译的文本了
我接下来会给你提供一个JSON格式的本地化文本,请你帮助翻译,,其中英语和俄语不需要翻译了,你可以用source作为翻译的来源,note作为翻译的说明,你还可以参考已经翻译的en和ru但不能修改它们,这些要翻译的语言可能被预先占位符占住,你可以直接替换调它,另外还有一部分字符是属于程序中支持插入文本的占位符,请也把它们放到合适的位置,你也可以根据情况决定是否要翻译某个东西,另外我的翻译文件支持markdown语法,你可以根据语境调整修饰的词等,各个语言都要尽量自然和贴合note中说明的使用场景, 明白了吗?

在本文发布的时候ChatGPT Plus只对极小部分用户开发了32k版本,而大部分用户还是8k版本,所以需要分段粘贴(可以用修改发送文字的方式给出新的文本,避免提示词的上下文丢失)
然后得到的翻译结果如下:
{
"Shared/Resources/en.lproj/InfoPlist.strings": {
"CFBundleDisplayName": {
"source": "Fruta",
"note": "Bundle display name",
"ru": "Фрута",
"zh-Hant": "Fruta",
"en": "Fruta",
"zh-Hans": "Fruta",
"ja": "フルータ"
},
"CFBundleName": {
"source": "Fruta",
"note": "Bundle name",
"ru": "Фрута",
"zh-Hant": "Fruta",
"en": "Fruta",
"zh-Hans": "Fruta",
"ja": "フルータ"
},
"NSHumanReadableCopyright": {
"source": "Copyright © 2020-2021 Apple. All rights reserved.",
"note": "Copyright (human-readable)",
"ru": "© 2020–2021 Apple. Все права защищены.",
"zh-Hant": "Copyright © 2020-2021 蘋果公司。保留所有權利。",
"en": "Copyright © 2020-2021 Apple. All rights reserved.",
"zh-Hans": "Copyright © 2020-2021 苹果公司。保留所有权利。",
"ja": "Copyright © 2020-2021 Apple. 保留所有權利。"
}
},
"Shared/Resources/en.lproj/Ingredients.strings": {
"Almond Milk": {
"source": "Almond Milk",
"note": "Ingredient name",
"ru": "Миндальное молоко",
"zh-Hant": "杏仁奶",
"en": "Almond Milk",
"zh-Hans": "杏仁奶",
"ja": "アーモンドミルク"
},
"Avocado": {
"source": "Avocado",
"note": "Ingredient name",
"ru": "Авокадо",
"zh-Hant": "鱷梨",
"en": "Avocado",
"zh-Hans": "鳄梨",
"ja": "アボカド"
},
...
}
JSON转换回xliff
需要的文本都被翻译完成后,我们就可以用这个JSON再转换回xlcoc并导入Xcode了,当然在导入前还需要人工检查一下,虽然GPT4加上翻译说明应该已经能比较准确的翻译应用了,但准确用语,复数支持,文本格式等复杂情况可能还需要人工校验一下,避免出现问题
接下来我们再使用下面的代码将JSON转换回xliff
import os
import json
import xml.etree.ElementTree as ET
# 这是你的JSON文件的位置
input_file = "/Users/nhuji/Desktop/Fruta Localizations JSON/translations.json"
# 这是你想要将新的xliff文件保存到的文件夹
output_dir = "/Users/nhuji/Desktop/Fruta Localizations XLIFF"
# 从JSON文件中读取数据
with open(input_file, 'r', encoding='utf-8') as f:
data = json.load(f)
# 确保输出文件夹存在
os.makedirs(output_dir, exist_ok=True)
# 获取所有的语言代码
language_codes = set()
for translations in data.values():
for translation in translations.values():
language_codes.update(translation.keys())
language_codes.discard('source')
language_codes.discard('note')
# 为每种语言创建一个新的xliff文件
for language_code in language_codes:
# 创建一个新的xliff根元素
root = ET.Element(
'xliff', {'version': '1.2', 'xmlns': 'urn:oasis:names:tc:xliff:document:1.2'})
# 为每个文件添加一个新的file元素
for original, translations in data.items():
# 创建一个新的file元素
file = ET.SubElement(root, 'file', {'original': original,
'source-language': 'en', 'target-language': language_code, 'datatype': 'plaintext'})
# 创建一个新的body元素
body = ET.SubElement(file, 'body')
# 为每个翻译添加一个新的trans-unit元素
for id, translation in translations.items():
# 创建一个新的trans-unit元素
trans_unit = ET.SubElement(body, 'trans-unit', {'id': id})
# 创建一个新的source元素
source = ET.SubElement(trans_unit, 'source')
source.text = translation['source']
# 创建一个新的target元素
target = ET.SubElement(trans_unit, 'target')
target.text = translation.get(
language_code, "") # 使用get方法,如果键不存在,返回空字符串
# 创建一个新的note元素
note = ET.SubElement(trans_unit, 'note')
note.text = translation['note']
# 将新的xliff文件保存到文件中
tree = ET.ElementTree(root)
tree.write(os.path.join(
output_dir, f'{language_code}.xliff'), encoding='utf-8', xml_declaration=True)
这样我们就得到了转换回来各种语言的xliff文件
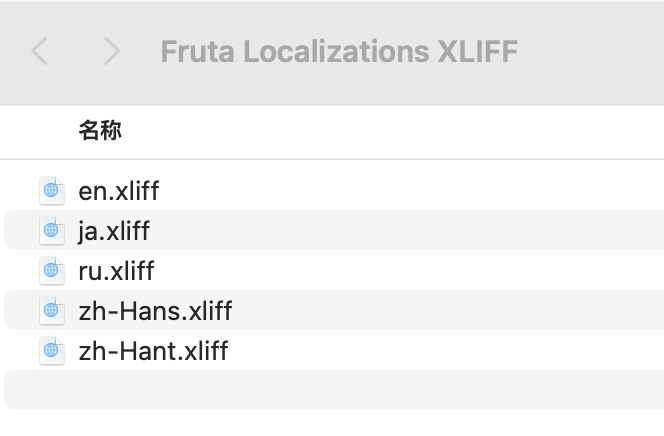
由于xlcoc的本质是Xcode Localization Catalog文件夹,所以不能直接转换,我们可以继续写程序让它放入对应的文件夹中,不过这里就不展示了,也可以直接把翻译好的xliff放入对应语言的xlcoc
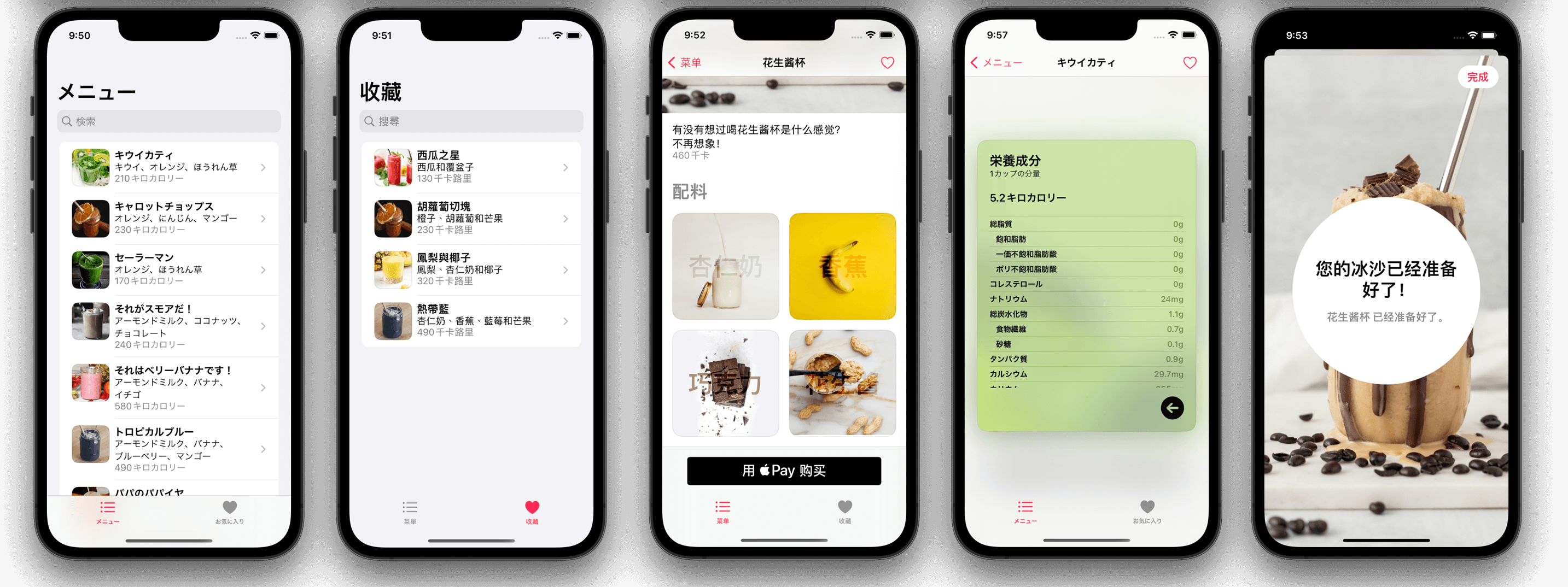
接着我们将翻译好的xlcoc文件再次导入Xcode,就可以看到我们的翻译成果了!
可以看到多种语言都顺利的支持了!包括需要插入的占位符等
相关资源和说明
- 文字代码的Github仓库
- 示例程序 Fruta: Building a Feature-Rich App with SwiftUI
- 使用了AI生成的封面图
- 目前8K版本的GPT4需要注意token限制,不然可能出现问题,使用更完善的API和自定义prompt来自动处理较小分段的翻译可能可以获得更好的效果(比如转换成JSON时按.strings文件分割,翻译都完成后再合并转换)
- 专业名词可以尝试先输入给GPT后再让它翻译来保持准确性
- 在GPT3.5使用的话,可能需要说明代号对应的文字,比如
zh-Hant为繁体中文 - 如果出现只翻译需要的部分的文字的问题可以要求"请在下面的文字基础上替换要翻译的文字"
- ChatGPT May 12 Version更新中官方表示"users can now choose to continue generating a message beyond the maximum token limit. Each continuation counts towards the message allowance."也就是说当生成的文字超出tokens限制时可以按
Continue generating继续生成