你有想过 Git 是怎么记录一个文件的不同版本的吗
请只考虑它版本控制相关的基本功能(忽略协作、冲突解决,远程、分布式等特性),我们可以把 Git 的主要功能分为
- 提交(Commits):保存文件的特定版本
- 分支(Branching):创建和切换不同的开发分支
- 检出(Checkout):切换到不同的提交或分支
- 合并(Merging):合并不同分支的改动
可以发现 Git 做的其实就是帮我们保存一份文件在记录下的不同的状态/版本,所以 Commit 命令就像是一个相机一样记录下文件当前的状态,然后我们可以通过 Checkout 命令来回到这份文件的不同的时期
如果让我们来实现这样一个文件的不同版本的记录 我们会怎么做呢?
我们很自然地就可以想到 那每次记录的时候,直接存一份变化后的文件就好了,事实上 Git 也是这么做的(你可能会觉得这样做的话,不是会存储同一个文件的 n 个只有细微差别的版本吗,我们接下来会说到这一点)
Git 会把我们每一份文件存储为一个对应的 blob 对象(你可以简单的理解为 Git 每次都会存储完整的一个文件到它的库中。虽然格式和原始文件不一样),这样当我们需要某个 commit 里的这个文件,直接把这个 blob 再次拿出来就好了
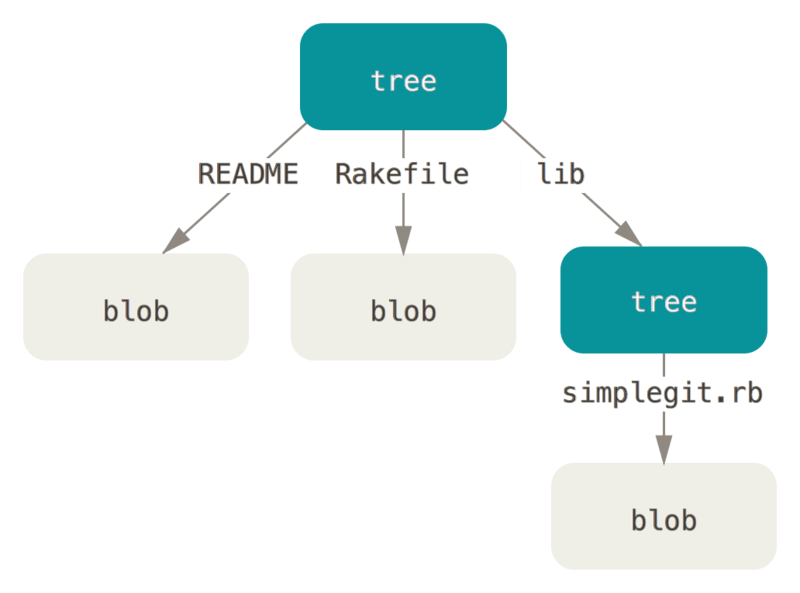
比如图中我们有 3 个文件,顶层目录(也就是最顶部的 tree )有两个文件**README** 和 **Rakefile它们各自对应一个 blob,而子目录 lib 里的simplegit.rb**同样也对应一个 blob
当我们把上图抽象一下它就像一个 commit,那么我们扩展一下把多个这样的结构联系起来就成了 多个 commit 组合成的 history,就像下图一样
其中黄色部分就代表了之前的图,整个部分作为一个 commit,而 tree 依然是目录结构,而它拥有的文件指向了它们各自对应的 blob,也就是米色的部分
他们左上角都标注了它们各自的 ID
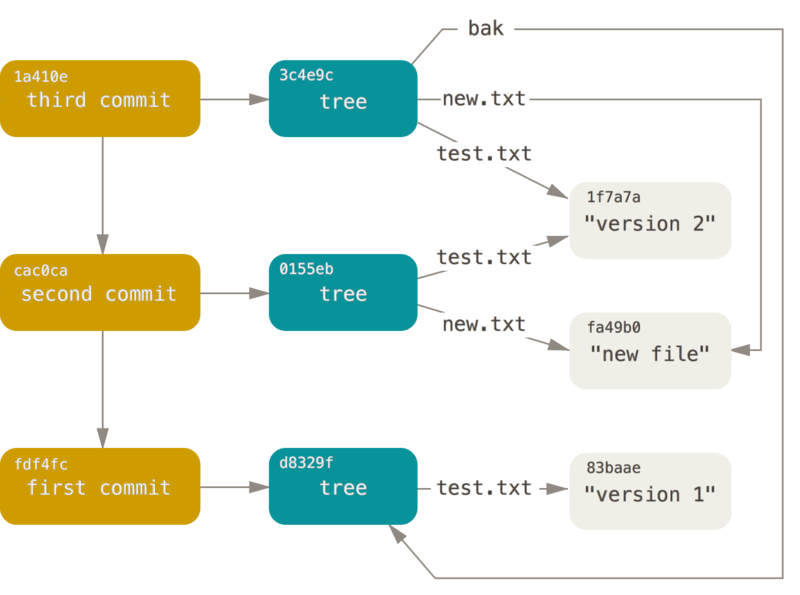
让我们来看看图中的例子
第一次提交我们创建了第一版的 test.txt 文件,于是 Git 有了一个对应 ID 为83baae的 blob
第二次提交我们修改了刚刚的 test.txt 文件,于是 Git 又另外保存了一个 1f7a7a 的 blob 来对应修改后的 test.txt
所以现在我们的 Git 存储库里有了两个完整的 test.txt 来对应它不同 commit 时的状态
接着我们继续在第二次提交时新创建了一个 new.txt 文件,因此也多了一个 ID 为 fa49b0 的 blob 来存储这个新创建的文件
在第三次提交开始前,我们可以发现我们的存储库里有了 3 个 blob 分别对应两个不同版本的test.txt 和一个版本的 new.txt
接着我们进行第三次提交,这次我们没有修改文件了,而是决定创建一个 bak 子目录,并且在里面放一份和第一次提交一样的 test.txt 文件作为备份(虽然有 Git 后完全不需要这样手动备份)由于这个备份目录里的 test.txt 文件和第一次提交时的test.txt 完全一样所以这次 Git 不会存储任何新的 blob 而是直接把 bak 目录指向第一次提交的 tree 就好了
所以来做个小结,Git 给每次变化的文件都存储一个对应的完整内容的 blob ,并且如果这个文件没有变化或者哪怕在不同目录存着和之前一样的文件, Git 也不会存新的 blob,Git 通过这样的方式完成第一次的去重 (哪怕文件名但内容一样也不会存多个 blob)
Git 怎么知道文件内容是否一样呢?
在上面提到 Git 会给每个东西都标记一个 ID,比如 commit、tree、blob 等,这也是 Git 用来判断文件内容是否相同的手段,Git 使用了SHA-1(Secure Hash Algorithm 1)加密哈希函数,它可以将任意长度的数据输入转换成一个固定长度的输出,也就是说它可以把一个数据/文件转换成固定长度的数字,而这个数字就是 Git 给 blob 的 ID
让我们来做个小实验
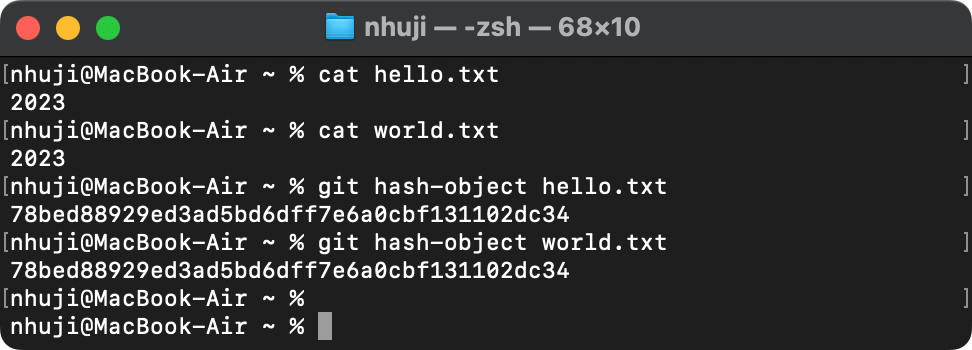
创建了两个不同 hello.txt 和 world.txt 的文件并且都写入完全一样的内容
然后通过**git hash-object**这个底层命令得到了 Git 计算的 ID
可以看到哪怕文件名字完全不同但计算出的 ID 是一样的,同样的接下来我把一个文件的内容稍微修改添加了一个点,可以看到计算的的 ID 完全不同了
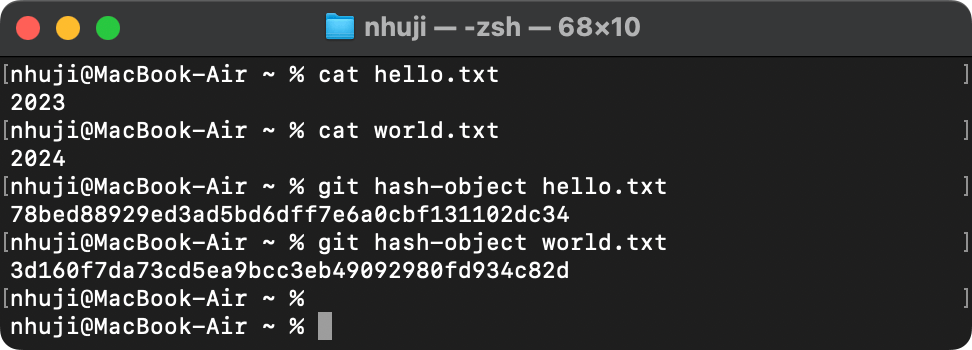
所以 Git 就是通过这样的手段识别内容相同的文件并存储 blob 后给于对应的ID作为引用,所以哪怕我们在一个仓库内把同一个文件放一百万份也只会存储一个 blob
那么多同一个文件的不同版本怎么避免冗余呢?
上面提到哪怕是同一个文件,只要有轻微的不同,哪怕一个字符不一样那么也会为它存一个 blob,所以虽然 Git 通过 ID 的计算对内容相同的文件进行去重,但依然会有同一个文件的 n 个不同版本的完整文件存储在库里的问题,如果这么做那么仓库会变得非常巨大,而且明显很不合理
这个时候 Git 就会使用另一种手段,也就是 zlib 压缩和增量储存技术,你在提交等操作时 Git 都可能会执行git gc 命令,将blob 通过压缩后再把类似的 blob通过增量技术打包成一个 packfile 文件,Git 打包时,会查找命名及大小相近的文件,来达到只保留差异部分的效果,比如它会选择一个基础版本然后再把其他版本的差异存储下来放入 packfile 中。
另外其实你也可以手动执行git gc 命令,特别你做了一堆文件更改并且想要推送到远程想要节省时间时。
所以虽然我们会觉得每个 commit 可能是下面这样的结构,每个 commit 里分别包含当前所有文件的引用(同一个文件不同颜色代表不同的版本)
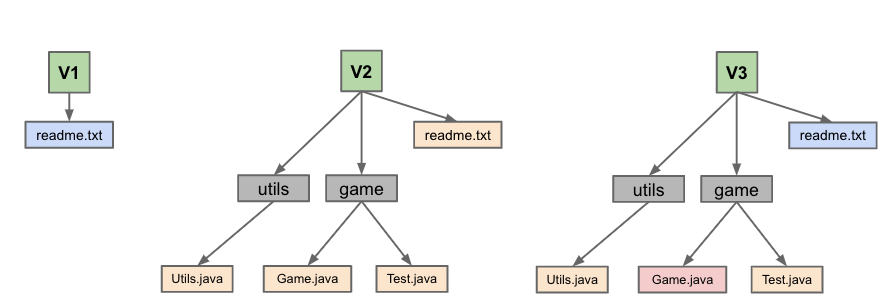
但实际上是这样的看起来比较混乱的,但其实内容一样的文件和目录只存一份的结构
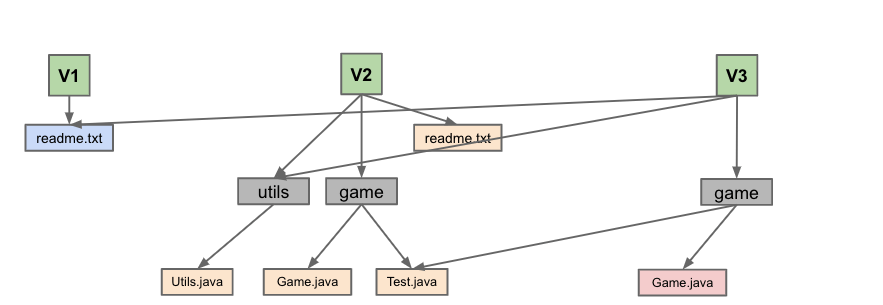
Commit 的结构
说完了单个的文件是怎么存储的,接下来说说 commit 的组织
首先我们可以发现抛开 Git 各种复杂的特性,它本质上遵循了函数式数据结构的思想,通过这样不可变的特性保证了我们修改的稳定,这也是为什么有人说 “Git 永远不会真正丢失任何东西”
为什么说 Git 的本质可以被看作一种数据结构呢 ****, 可以参考一下《Git is a purely functional data structure》
可以说每次 commit,哪怕我们是修改或者重写之前的 commit 其实都是在之前的基础上新增信息而不是修改原有的信息,这一点和函数式数据结构非常类似
这篇文章里其实对Git 怎么进行 commit、rebase、merge 介绍的原理介绍得比较清楚了,所以下面就简单的说一说 commit 本身的结构
一个 commit 可以分为下面几个部分:
- 父提交(Parent Commit)的引用
也就是指向它前面的那一个提交的引用,非常类似于单链表 - 元数据
也就是这条提交的作者是谁,时间是多久、提交的信息(也在就git commit -m 里的写的东西)等等 - 对文件的引用
也就是之前提到的 blob,一个 commit 里会包含对所有文件对应的 blob 的引用
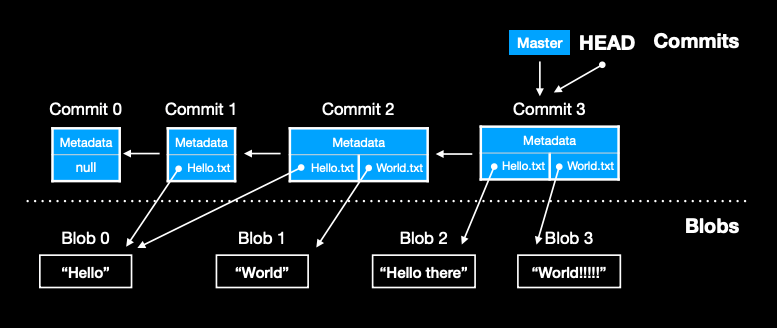
比如如图,每个 commit 都有关引用指向他们的父提交,而他们本身也有对文件 blob 的引用,比如在 commit 2 里新增了 World.txt 但是没有修改 Hello.txt 所以它依然指向 blob 1
当然分支和 head 这样的指针其实也是有对对应的 commit 的引用的
Git 是怎么管理这些文件的
现在我们知道了 Git 怎么高效地保存一个文件的不同版本,commit 的结构是怎么样的,那么它又是怎么组织这些东西呢
让我我们以这个简化后的图作为说明仓库的说明
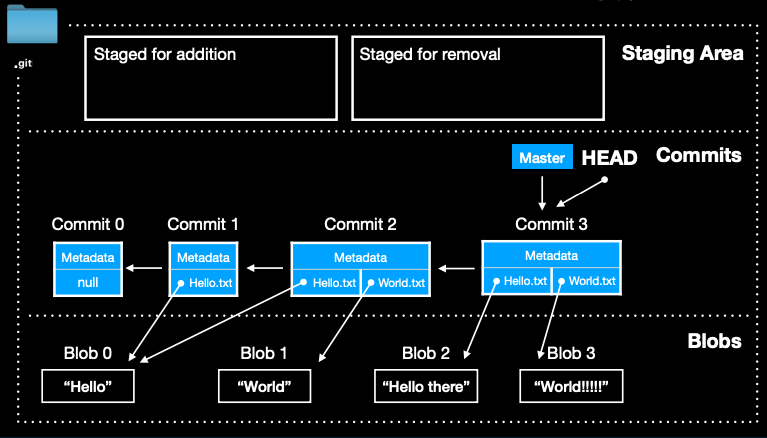
我们可以把仓库分为三个区域:暂存区、提交、文件存放
暂存区
在 Git 中,暂存区(Staging Area)用于记录下一次 commit 将包含哪些内容
我们可以将暂存区视为两部分:一部分是准备添加到下一次提交中的文件(Staged for addition),另一部分是标记为删除的文件(Staged for removal)
当你执行 git add 命令时,你实际上是在告诉 Git 将更改添加到暂存区的添加区域
比如下面我们 init 了仓库,然后创建了一个文件并 git add hello.txt
这时就能看到我们把这个文件存储了一个 blob(也就是放在了文件存放区),并且设置了一个引用到 Blob 0

如果我们进行 commit 的话,暂存区的部分就会作为我们 commit 的信息
所以这个时候我们 commit 仓库就得到了 commit 1,仓库也就变成了下面这样
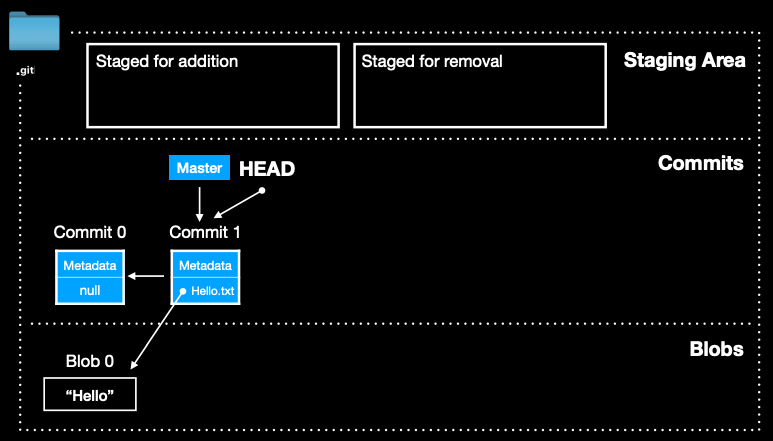
提交
这个部分能就记录了我们各个提交具体内容,和提交之间的关系,还包括 HEAD 和分支还有他们指针的信息
文件存放
Blob 是 Git 用来存储文件数据的对象。每当你创建或修改文件并将其添加到暂存区时,Git 会为文件内容创建一个新的 blob。Blob 对象与文件名无关,只与文件内容相关。这意味着如果两个文件内容相同,它们会共享同一个 blob,即使它们的文件名不同
结语
通过上面介绍的 Git 保存不同文件的版本的方式,以及怎么压缩管理这些文件,怎么组织 commit,怎么对 commit 进行各种操作(在引用的那篇博客里有详细介绍)和 Git 仓库的结构,也许 Git 可能不再那么像一个黑盒了吧
当然依然有很多内容没能展开,比如Git 仓库里的文件太多了后怎么快速获得呢,新的 commit 具体怎么链接之前的 commit、为什么说 Git 有纯函数式数据结构的特点等等
其实根据上面的原理,利用比如 Java 的对象 序列化等 我们也能很轻松的做一个进行版本控制的命令行工具 因为我们现在知道 Git 的本质就是一个纯函数式的数据结构,所以也不需要复杂的更改逻辑,只要新增信息来达到修改的效果就好了,而它对文件的版本控制其实就是每个改动的文件都存一份完整的 blob 然后再压缩,并且也清楚仓库的大概结构,所以虽然真正的 Git 有各种无比复杂的功能,但核心其实和我们在做的任何程序都没有本质区别,也没那么复杂。
参考资料
结构图:
https://git-scm.com/book/en/v2
仓库图:
https://cdn-uploads.piazza.com/attach/k5eevxebzpj25b/jqr7jm9igtc7l5/k97ipfmgmb3n/Gitlet_Slides.pdf