之前和别人介绍 ChatGPT 的 DALLE 3 画图时, 似乎很多人对生成的图片里的文字很在意, 比如错误的拼写, 没办法放入一段长文字之类的问题, 但也许很快就不会再是问题了
本篇将介绍 GPT-4o 的图片生成能力! 为什么会有个 o 在后面呢~ 其实“o”代表“omni”,源自拉丁语“omnis”,意为“全能”或“全部”。代表了 4o 的多模态能力,能够处理文本、音频和视觉等多种输入和输出形式,也就是说他可以真正接受你对他语音说的话, 能看懂你给他发的图片等, 不仅如此 他还能输出音频和图片, 是非常巨大的进步,目前还没有其他模型能做到这一点
顺便简单整理一下 GPT-4 系列模型的发展:
GPT-4:2023 年 3 月 14 日发布 相比 ChatGPT 公布时的 GPT-3.5 大幅提升了智能程度
GPT-4V:2023 年 9 月发布,首次支持图像输入, 也就是可以理解你发送的图片
GPT-4o:2024 年 5 月 13 日发布,也就是我们今天要介绍的模型,支持多种输入和输出的多模态模型,图片理解能力相比 4V 也进步了很多, 发布后逐步放出该模型的各种能力 (比如已经推出的音频输入输出能力, 和下面介绍的还未推出的图片输出能力)
(还有类似GPT-4-Turbo这样能力没有太多变化, 但是速度/上下文窗口提升, 成本降低的版本)
图形输出能力
需要注意, 以下是已经公布 但是还未开放给用户使用的功能 现在我们还不能使用, 仅作为对未来发展的预览来介绍, 相信它正式开放使用后能对目前 AI 生成图片带来很大改变
简单的说, 你可以把文字,图片,音频都一起给 4o, 它能直接理解 而不是依靠其他工具转换成文字再处理, 而输出同样也是, 它也支持文字, 图片,音频的输出. 就像它是原本只会通过盲文阅读文章和写字来和你沟通的聋哑盲人, 突然获得了视力和听觉, 并且掌握了出色的喉咙(模仿各种声音)和绘画技能. 4o 的音频输入输出能力, 我们现在已经能在 ChatGPT 体验到了, 被称为高级语音模式, 和传统的语音转文字再给 GPT 不一样, 所以也能做到很多以前做不到的事情, 不过这个就留给以后的文章介绍了
今天要介绍的功能, 实际上在今年五月 4o 发布时已经公布了, 不过只是很低调地在官网给了几个例子, 所以当时并没有引起太大的关注, 而且直到现在依然没有消息告诉我们多久能用上, 不过就当是抢先剧透了解一下未来吧, 让我们一起来看看
上次我们说过 ChatGPT 目前生成图片是靠它根据我们的要求写了一段英语提示词再交给 Dalle 3 生成的, 这就有很多坏处, 比如它并不能真正的控制生成的图片, 也无法查看生成的图片, 更没办法按照我们的指令由它自己连续地修改同一张图片等, 而且还有上面提到的文字老是写不对的问题
但这一切问题在 4o 自己可以输出图片后都大幅度的减轻了, 并且能做到很多原本非常难以做到的事情
让我们通过从官方公布的示例中选取一些比较特别的例子来说明吧
示例 1 强大的图片加入文字的能力
图片故事:”机器人遇到写作瓶颈”
示例中橙色代表我们的输入,而蓝色是 GPT-4o 的输出
用户要求以下面的特定视角画出机器人打一段话, 右边是它给出的图片输出(依靠它模型本身,而非现在的调用其他模型)
我们可以看到图片上准确而清晰的在纸上写出了用户要求的文字, 这种图片上大段的准确文字在现有的任何图片生成模型上都难以完成

接下来的聊天中,用户追加了更多文字的要求,也完美的显示在了图片上, 并且 4o 还给了特写, 我们可以看到图片的画风 比如打字机的外观保持了和上一张图一样的特征, 这也是现在其他文生图模型中需要花费额外的努力才能做到的一致性

最后用户要求一张机器人撕掉这篇文字的提示,可以看到即便断成两半文字依然清晰和连贯,并且有一些纸的曲面的效果 这里机器人的手的外观也和第一张图一样

上面这个示例中 4o 能像处理文字一样处理图片时, 因此它可以很精细的按照你的要求和它的理解来生成准确的 、系列的图片
当然,是否支持中文或英语以外的文字 还需要等正式公开使用才知道了, 不过我想既然已经支持了英语,那么未来对中文的支持也不会太远了
示例 2 人像处理
现在我们直接给 ChatGPT 图片要求它生成和你给的图片类似的图片的话, 流程是这样的:
你给出图片 → GPT 模型理解 → GPT 写出文字提示给其他模型生成 →得到你要的图片
这个流程中,虽然 GPT 已经能理解你给出的图片了,但又于没法直接输出图片, 所以会有转换成文字的过程, 而就会大量的失去图片的信息, 并且这对调用的图片生成模型的还原文字提示词的要求也很高 总之....结果就是 生成的图片和你给的图片南辕北辙
比如我给出一张图片,要求 ChatGPT 帮我生成类似的图片,可以看到他虽然理解了这是一张像素艺术的圣诞火车穿过夜晚覆盖着雪的村庄的图片,但因为必须转文字后给 Dalle 3 来生成,所以像镜头角度,画风细节等都丢失了,和我们想要的“类似的”图片,不能说没关系...只能说关系很小 😂

但像 4o 这样模型本身支持图片输入输出的话, 那能想到的很简单的一个用法, 就是你可以给它一张你的照片然后要求他给你某种风格的图 就像下面这样给他一个照片让4o画出一个漫画版, 因为能理解和输出图片, 所以细节还原得很到位 而不是描述你的长相再让其他人画出来 (这就类似于坐着一排人 从头到尾传话的游戏,传到最后已经完全不对了)
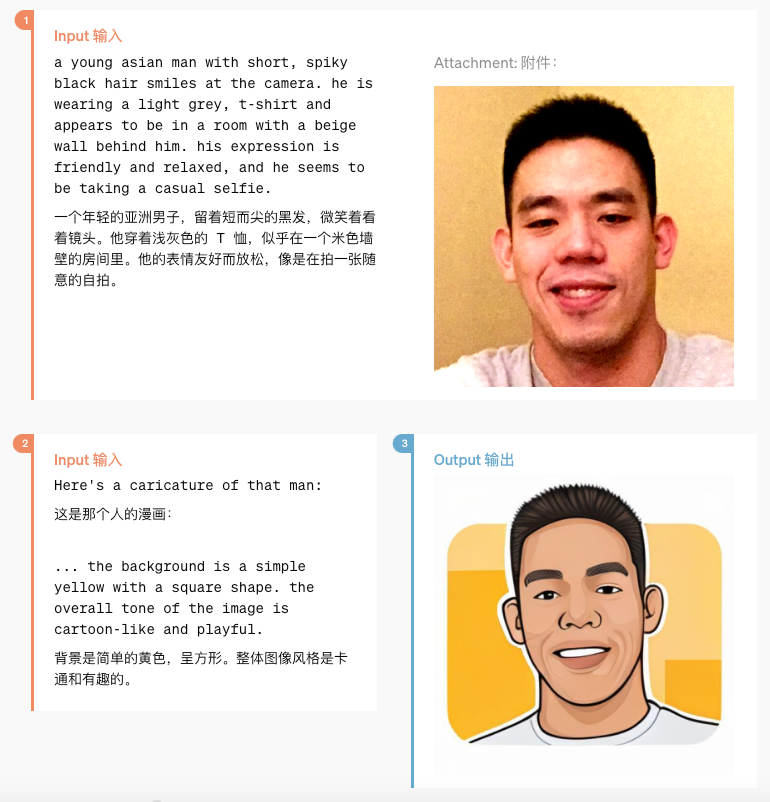
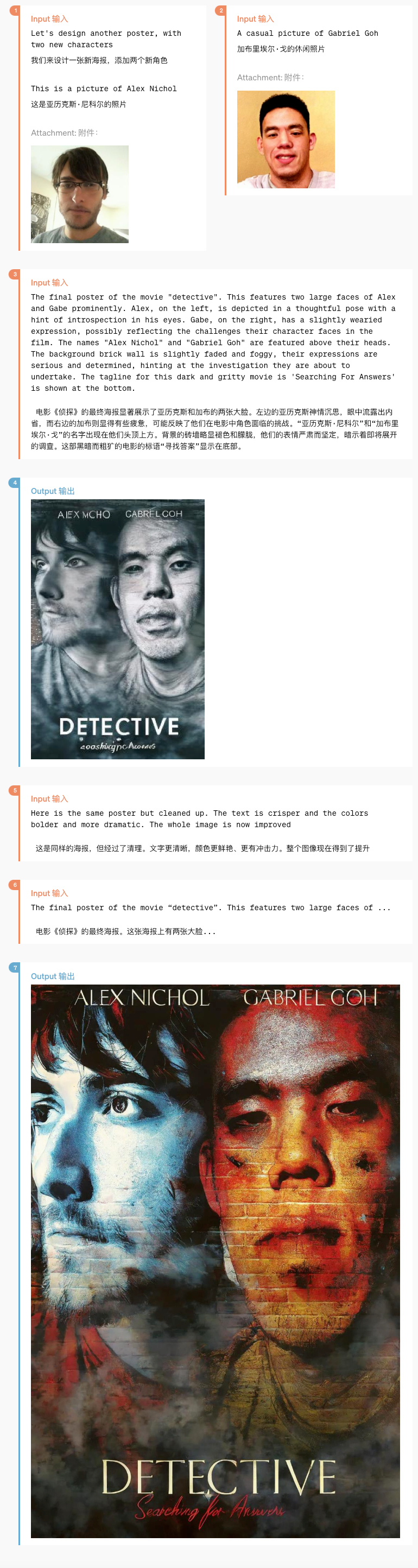
更进一步的是,你甚至能提供两个人的照片,来让它为你制作一副电影海报, 可以看到最后的海报人脸的角度和提供的照片并不完全一样, 不是直接把两个人去掉背景 p 在一起, 而是它记住了人物的特征再输出的(就像 GPT 可以处理你给出的文字来改变文字风格 比如更专业 更轻松一样,它也能把图片也当成类似文字这样来处理)
示例 3: 设计
4o 的这种多模态能力甚至能让它为你设计专属的字体:

或者给出 logo 和杯垫图片,让它把 logo “印”到上面

示例 4: 空间感
因为有良好的一致性和智能, 就像拥有空间想象能力一样, 你甚至可以要求它生成几张图片, 然后就可以拼接成一张动图
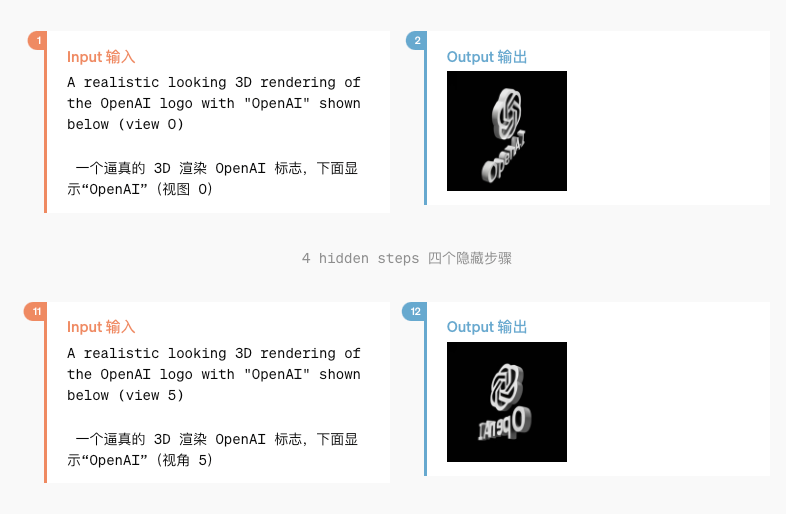
(依次生成了 6 张不同角度的 OpenAI 的3D logo图)
拼接这些结果就可以得到下面这样看上去是 3D 渲染出来的动图


基于 GPT 自己输出的图形也许精致程度没有现在各类图片生成模型的惊艳, 但技术路线差别很大, 能做到许多现在难以做到的事情, 就像GPT 以前人们需要对待各个任务都做出不同的 AI,但现在一个 GPT 已经能完成各种各样不同的任务了一样

(⬆️ 4o 生成的一张图)
上面这些都是OpenAI 官方放出的例子, 也就是现在 4o 这个模型真的能够做到的, 不过由于安全和计算资源等限制,我们还不能体验到 而且可以预见是为了防止滥用,最终推出的版本可能会有很多限制