LLM 究竟是什么呢? 一方面,它确实有一些非常神奇、令人惊叹的能力;另一方面,它在某些方面也并不擅长。所以, 在这个对话框背后究竟是什么?我们输入任何东西,按下回车,会出现一段文字——产生这些文字的原理是什么?我们到底在和什么“对话”? 相信如果我们能大概了解它的能力,也对我们更好地使用它有很大的帮助(而不是说我们真的要去训练模型)
接下来的几篇文档里, 将会介绍一个典型的 LLM 的训练过程 (主要参考了 Andrej Karpathy 的介绍)
数据集
所以类似 ChatGPT, Claude 这样的东西,是怎么“造”出来的?
要构造 ChatGPT 这类模型,一般会经历多个阶段,依次串行处理。第一个阶段叫做“预训练”(pre-training)。在预训练阶段开始时,第一个步骤就是:下载并处理互联网数据。直观地说,模型背后的公司需要把互联网的文本内容抓取下来,进行整理过滤,让模型进行“海量阅读”。
比如 Hugging Face 公司的 “Fine Web” 数据集, 就会把互联网内容精简到最终 44TB 左右的文本数据

像是 OpenAI、Anthropic、Google 等在训练时也会有类似的做法——从互联网上收集大规模、高质量且多样化的文本,并对其进行层层过滤。例如要保证文本足够多元化,又要保证文本质量,还要剔除大量无意义的垃圾内容。
常见的互联网数据来源:Common Crawl
很多公司会从 Common Crawl 拿数据。Common Crawl 是一个公益组织,从 2007 年开始就在全网爬取网页,截止 2024 年已经爬取了 27 亿个网页。它们会不断遍历互联网的超链接,获取各种网站的数据存档,并保存这些网页(主要是 HTML 页面)。但这些数据是非常原始的,所以在拿来使用前会有很多后续加工。比如下面这些步骤:
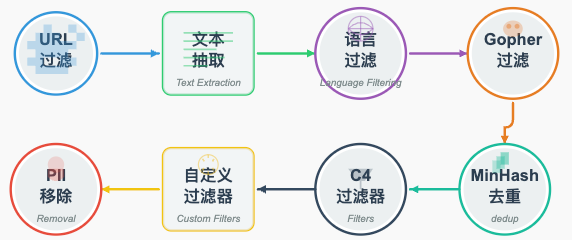
(Claude 帮忙画的图,还不错吧)
- URL 过滤:一些恶意网站或不良内容的网站(比如恶意软件、垃圾营销、极端内容、成人站点等)会在这一环节直接排除。(使用比如 https://dsi.ut-capitole.fr/blacklists/ 这样的列表)
- 文本抽取:HTML 网页有各种标签、CSS、JS,我们只想要其中的正文文本,所以要用一些算法/启发式方法尽量把网页上的“正文”文本提取出来,导航栏、广告之类都要过滤。
- 语言过滤:比如 Fine Web 只保留主要为英文(超过 65% 都是英文)的网页。其他语言就排除。这带来了模型语言能力差异:只学英文文本,模型可能只擅长英文,不太擅长比如中文等其他语言。但大模型也有一定的迁移能力,一种语言里学到的知识也能用另一种语言表达出来
- 去重:如果相同或类似的网页重复出现,需进行去重。
- 敏感信息剔除:比如检测到社保号、信用卡号、电话等隐私信息,就过滤掉。
总之,会有很多这样的清洗工作。最终拿到的,就是一个规模可能几十 TB、基本都是可读文本的大型语料库。然后才能进一步进行“喂给模型”的下一步。
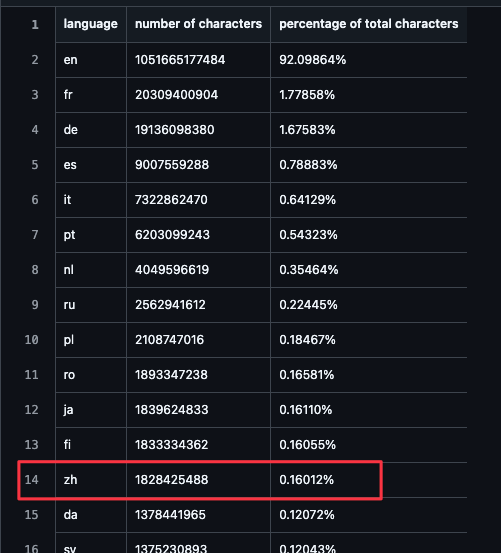
比如我们拿 OpenAI 在训练 GPT-3 时公开的数据就能看到,按字符算, 中文资料就只有 0.2% 不到的样子
然后占比的和权重的话, 我们可以从 GPT-3 的论文看到, 我们上面提到的 Common Crawl 是占比最多的
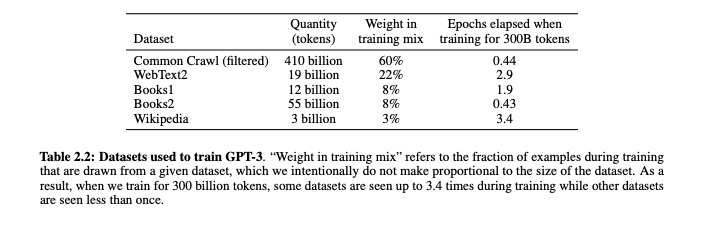
按数量和比例, 排名的话权重最高的是 OpenAI 自己专门筛选出来的高质量数据集 WebText , 像维基百科这种知识可信度很高的来源权重也比较大
将文本表示成 token 序列
接下来是个关键问题:我们如何把这么多文本,喂给一个神经网络?神经网络擅长处理向量形式或有限离散符号序列。文本本身是字符串,对应到计算机内部一般是 UTF-8 字节序列,但直接用单个 bit 或单个 byte 做输入会过于低效。
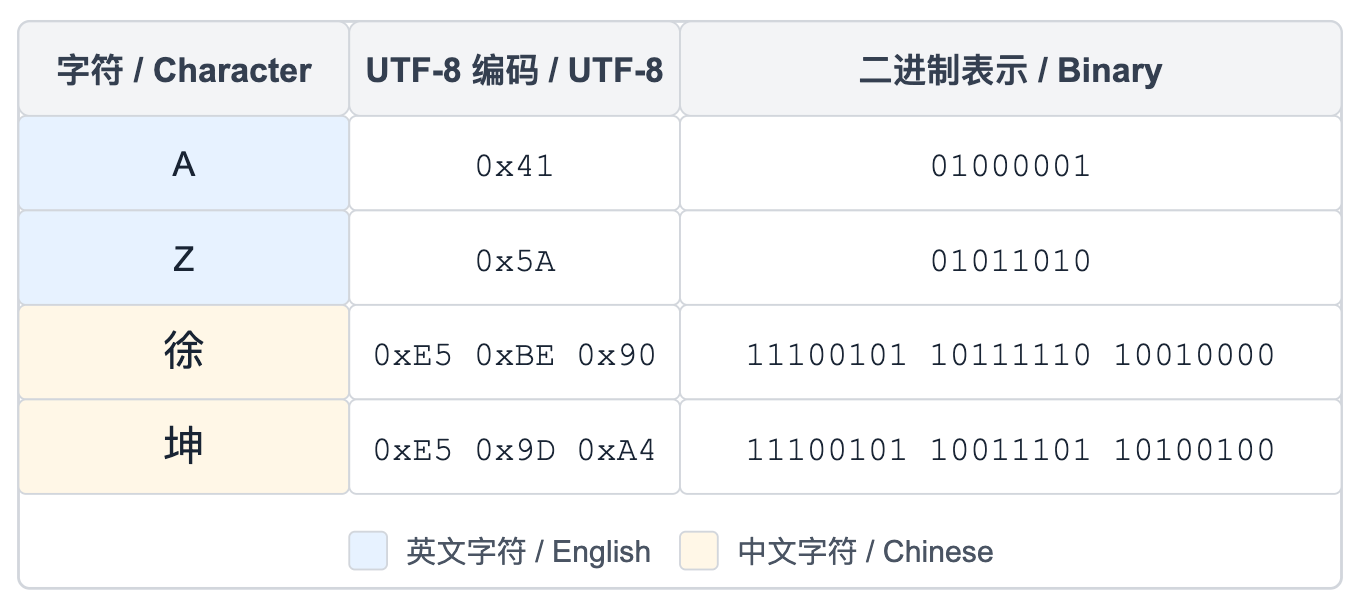
字符在 UTF-8 时的对应就和文本和 token 的对应类似
就像是UTF-8 文字编码的对应, LLM 里会使用一种 “分词” 技术,也叫 tokenization,也是将文本对应成一个个 token 。每个 token 代表一个文本单元,以减少序列长度。这些 tokens 可以是单个字符、单词的一部分,甚至是整个单词或句子片段
比较常见的一种方法是 Byte Pair Encoding (BPE) 或衍生的方法。它会根据文本统计,自动将常见的子词或字符串组合成一个 token,从而减少序列长度。
现代大模型通常用 5 万到几十万规模的 token 词表(vocabulary)。例如 GPT-4 使用了 100,277 个 token 的词表。然后,给定任意文本,就能被分割成一串 token,每个 token 其实就是一个 ID(数字),模型会把它们作为输入。
例如 “Hello world” 可能会被切分成 2 个 token: [Hello] 和 [ world];如果加了大写或符号,分词可能会不同。同样一句话在不同模型上也可能产生不同数量的 token, 因为用的分词表可能有差异, 当无法将一个字符作为完整 token 处理时,分词器会将其分解为字节级别的组成部分
文本怎么被分词
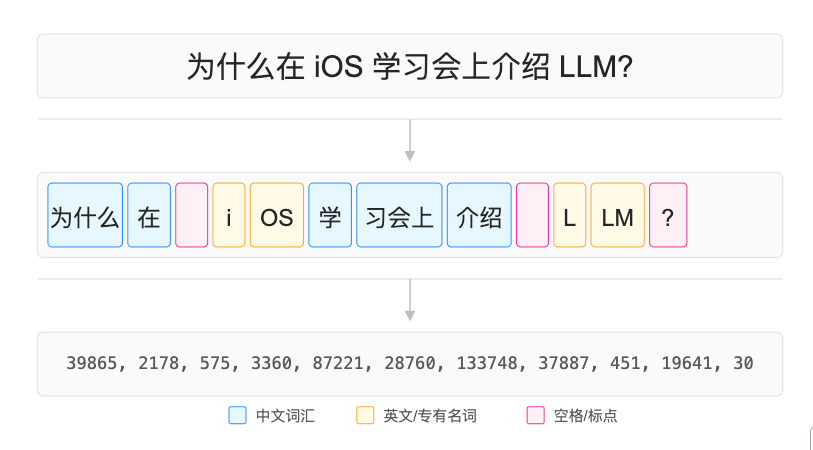
比如我们乱写一句中文, 可以看到它被分成多个 tokens 来对应词
那么聊天时的整个上下文,怎么被分成 tokens 可以在 Tiktokenizer 上看到 ⬇️
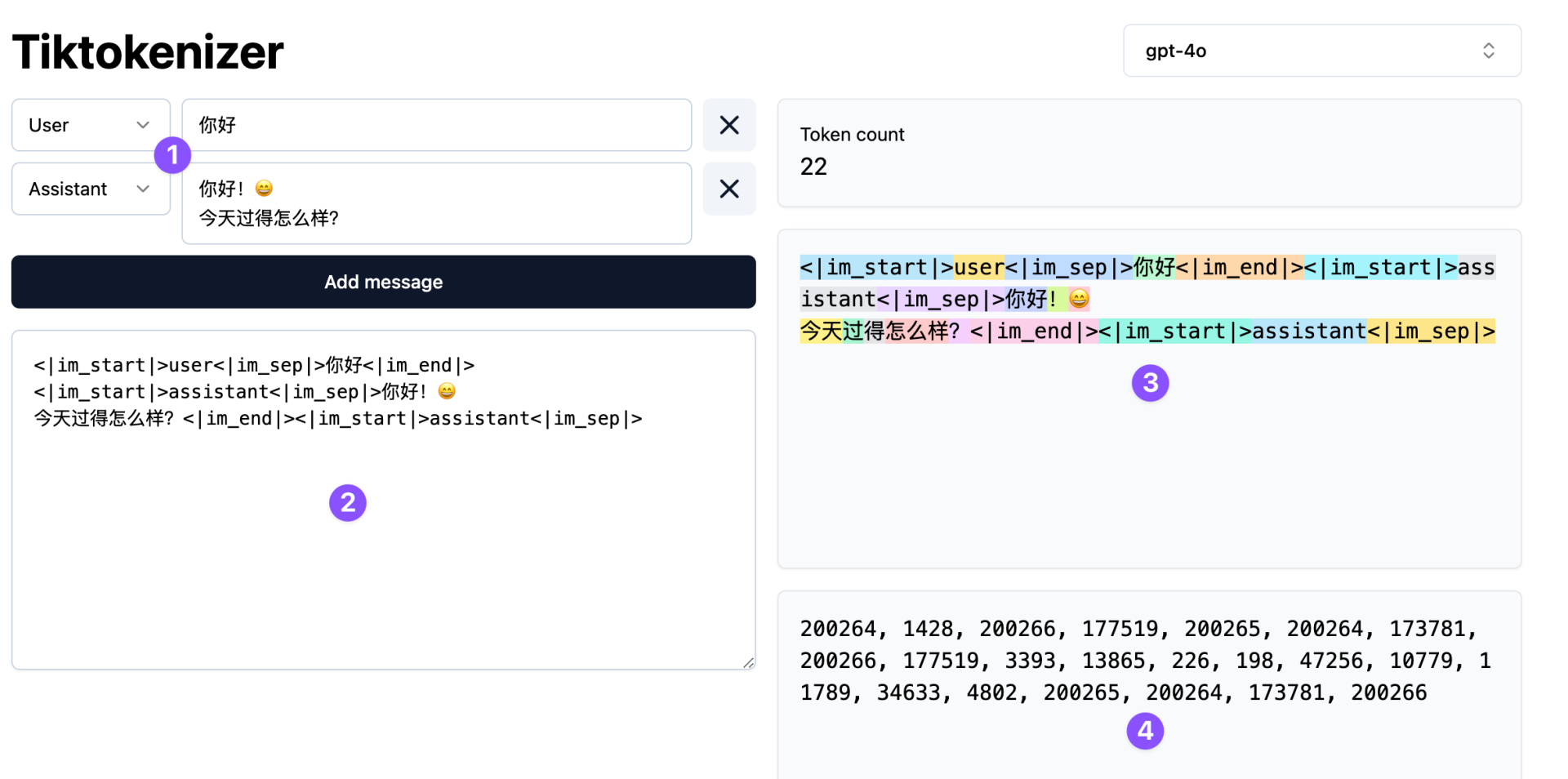
比如 1️⃣ 那里那样的简单的对话, 在处理时约等于 2️⃣ 的文字序列,其中<|im_start|>这样的标签和里面的文字用于区分用户和 AI 的回答和内容
经过分词后,就像 3️⃣ 那里将整个文本序列分成多块,对应 4️⃣ 的数字 tokens 序列, LLM 就会在这个基础上接着预测来处理,然后返回的内容就是 AI 对你的回答了, 也可以看看官方的分词器来看看一句话大概有多少 token OpenAI Platform
如果好奇数字和文本是怎么对应的,也可以看看下面这个 GPT-4 里 token 和文字的对应的分词表
简单的总结一下之所以不用文本而是要 token 化 是这样计算效率更高,也能支持更多的语言,加快训练速度,而且不光是文本, 图像和音频也能被 tokenization
这也解释了,为什么 LLM 的数学不太好,数不清楚 9.11 和 9.9 谁大, 或者 Strawberry 里有多少个 R
比如, "9.11"被分词为["9.", "11"],而"9.9"被分词为["9.", "9"],
在比较时,这样模型在比较时,容易将其视为字符或字符串的比较,而不是数值大小的比较,
由于11 > 9,它错误地得出9.11 > 9.9的结论,
所以这也是为什么 LLM 不擅长数学计算,
但如果明确要求模型进行逐步推理(chain-of-thought)或调用外部计算工具就能解决