今天想介绍一下 GPT 本身, 在这个 AI 快速发展的时代,无论是在工作中还是日常生活中,我们都越来越难以避免与 AI 技术的交集。特别是自 ChatGPT 问世以来,这样通用的大模型展现出了无穷的应用 —— 它能写诗、写代码、答疑解惑,进行自然的对话,甚至和你一起玩文字冒险游戏。例如已经推出的高级语言模式, 这种在几十年前的科幻电影中都是难以想象的场景,而如今却已成为现实。
大家在尝试向 ChatGPT 提问时, 有时候它的回答让人惊喜,有时候又不尽如人意
但不管怎么说我想我们现在能和电脑进行这样的自然的语言的沟通这一点本身就很神奇了,对吧?
很多人会混淆 ChatGPT 和 GPT 这两个概念。简单来说:
- GPT (Generative Pre-trained Transformer) 是基础的语言模型
- ChatGPT 则是基于 GPT 构建的一个对话应用服务
首先我想我们需要分清楚 ChatGPT 和 GPT并不完全等同,ChatGPT 是使用 GPT 构建的一个在线的应用服务,当我们说到 LLM 或者说大语言模型时说的就是 GPT 本身,所以他们其实不能混为一谈
首先解释一下 GPT 的意思吧,它的名字 Generative Pre-trained Transformer 就已经很好的说明了它的特性了,它是 生成式的,预训练的, 转换器
当然这些AI术语比较复杂就不管它了,简单地说它的作用就是生成各种文字,而且看来非常自然
但是有人觉得它的内容经常看着没问题但却是错的

因此也有人说他是狗屁通,因为生成的文字看起来很像那么一回事,甚至很多时候一本正经的在胡说八道,比如有人用他写论文也遇到虚构文献的情况,编了很多看起来不错的引用,但搜索发现全是不存在的文献
其实这就是人们对它技术不了解,没能正确使用,对它有错误的期望 所造成的问题
预测下一个词

如果我们用一句话总结GPT是干什么的,其实它所做的就是预测下一个词而已,
它本质上的目标是以模仿人类的方式,续写出流畅的文字
而且在续写时它并没有一个整体的规划 (当然 o1 这样的推理模型出现后这一点就不一样了)
它是一个字接着一个字生成的,这些生成的字的依据 来自于训练它的无数的资料,
比如下面这些:
- 论坛的贴子
- 社交媒体内容
- 人类这么多积累下来的书籍
- 学术论文
- 新闻文章
- 代码仓库(在提升 AI 的逻辑能力上相当重要)
当然在 24 年后,人类几乎已经穷尽了所有能收集到的公共数据, 靠堆数据量来提升 LLM 能力的做法已经遇到了瓶颈
另外在它刚出现时, 有人误以为 ChatGPT 的吐字是一种前端的打字特效,但实际上 GPT 模型确实是在一点点地生成文字并传输给你
让我们举个例子,比如我们说到“天空是”然后后面接一个一个词的话,各位觉得会是什么
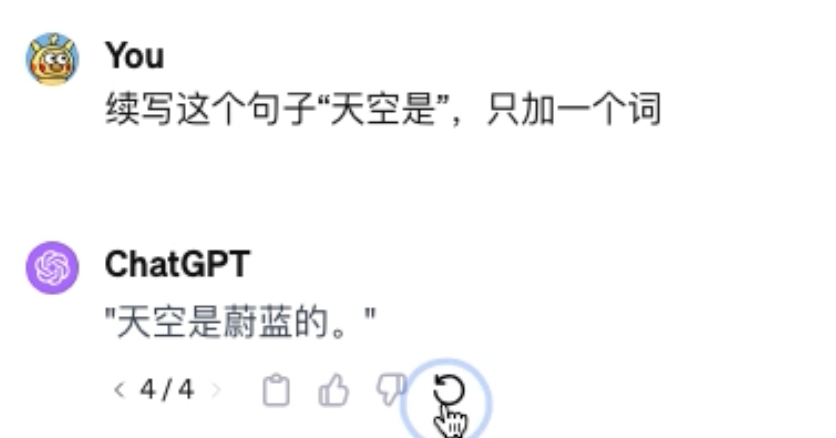
对我们很自然就想到蔚蓝的,对于 GPT 也是如此,多次尝试重试都是这一个回答
所以对于 GPT 来说就是根据前面的文本,然后预测下一个字最可能是什么,就这样一个字接一个字不断地按照概率预测, 最终生成了一个自然的回答
当然有人会问,那岂不是一样的问题, 得到的回答都一模一样?

但我们都知道,实际上 ChatGPT 每次回答的文字都是不太一样的
所以这里我们就要提到一个概念, GPT 在预测的时候还会有一定的随机性
温度值 ( Temperature )
在 AI 领域里控制随机性的设定叫做温度值,它用来决定模型在概率上的偏好,比如在接近 0 时模型会倾向选择概率最高的词汇,这样回答会更稳定,一致 但也缺乏多样性
而接近 2 的时候, 模型会考虑相对来说 概率没那么高的词汇,这样会更具有随机性和创意,但也可能显得 回答不怎么相关
让我们来做一个对比,注意这里使用的 GPT 不是我们常见的用于聊天的版本,而是我之前所说的那样,用于续写文本的原始版本
那让我们开始生成
首先温度值设定到最低, 也就是说随机性没那么高, 结果每次出现的结果几乎就是一样的
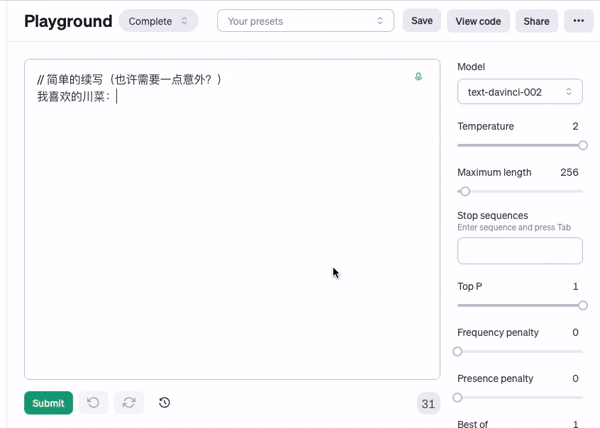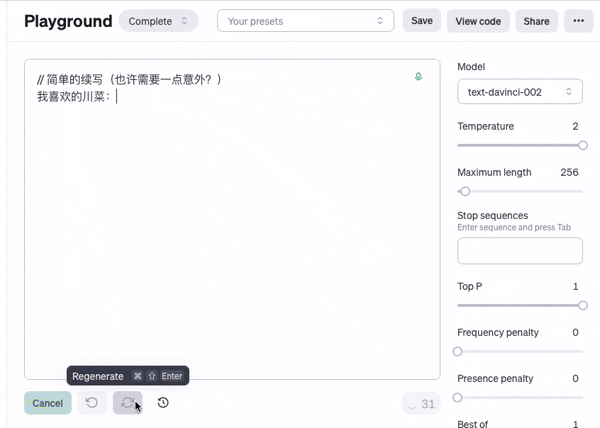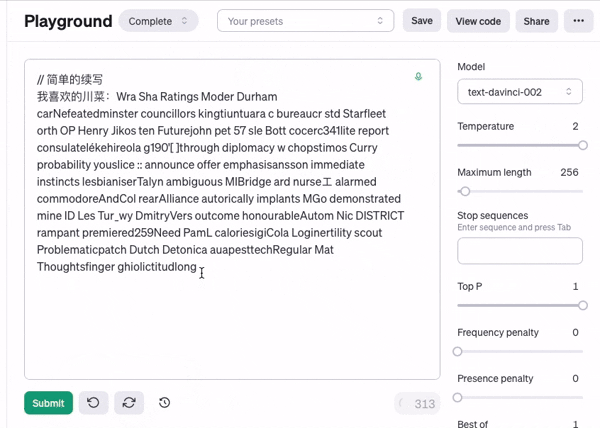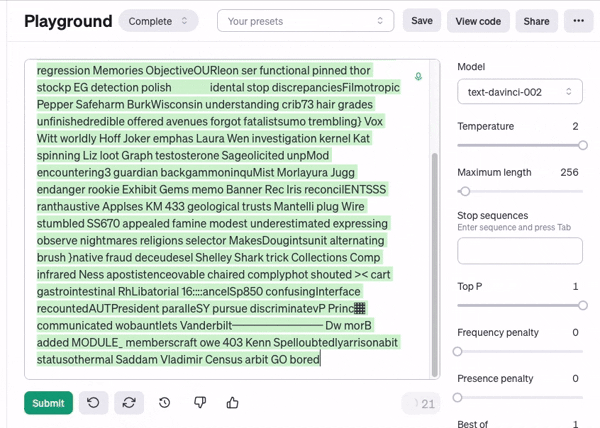
接下来我们将温度值调到最高....由于过于随机,生成出来的甚至不是人类可以读懂的文字
可以说完全就是乱码了
接下来我们把温度值调到稍微有一点随机的程度看看
可以看到因为不断的依据概率预测,且随机性没那么,GPT 陷入了一种类似于死循环的情况,因为按照概率来说一但重复的模式形成,那么接下来一样重复就是最高的概率了( 因为这里我们使用的是 GPT3 的早期版本,后面的 3.5 和 4 已经很少出现这样的情况了)
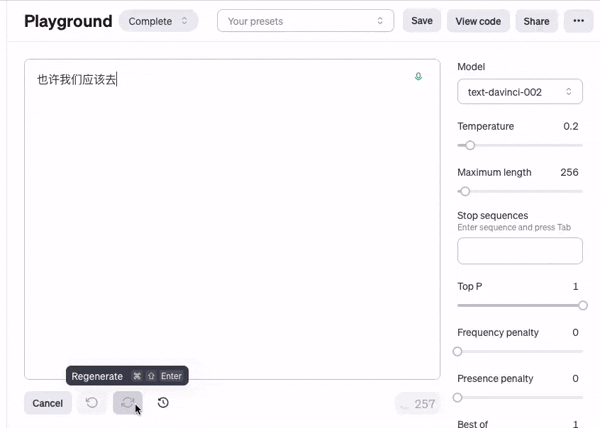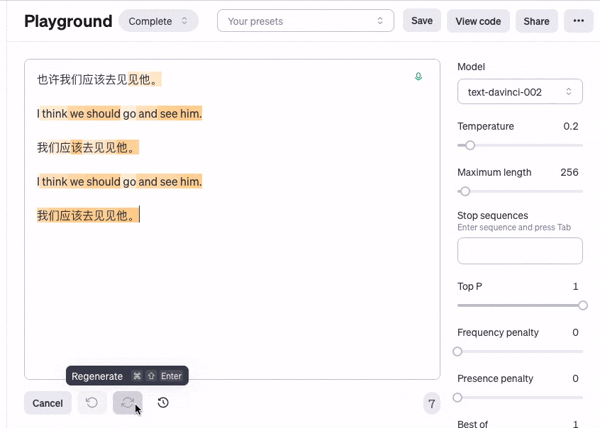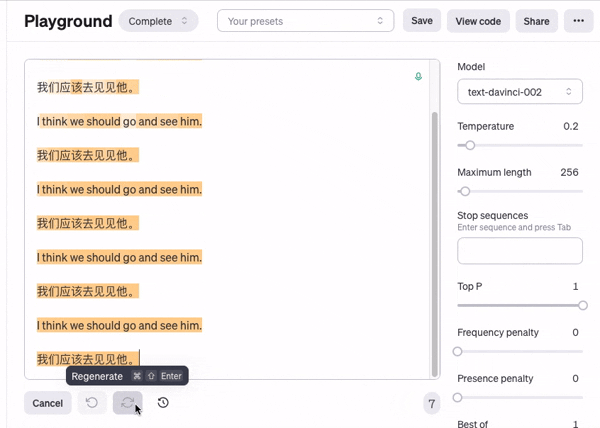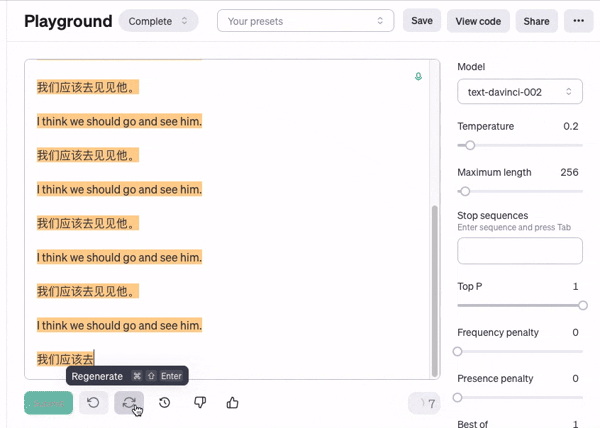
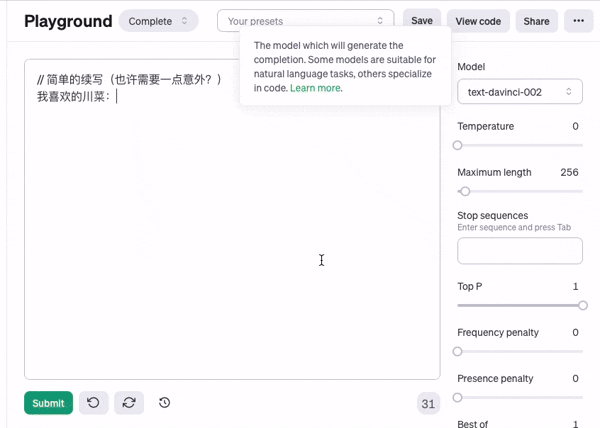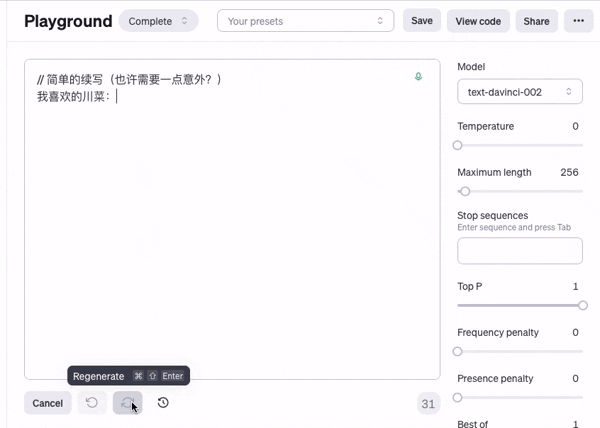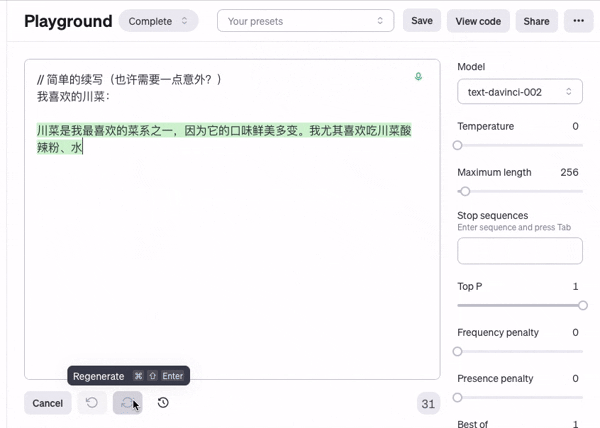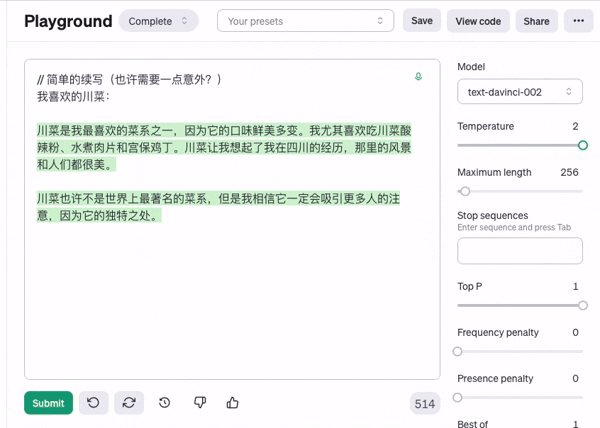
正是因为每个字的概率都有轻微的不同,最后积累起来得到的文本差别会很不同, 而不是每次都生成一模一样的内容,
注意这里橙色的部分, 就是模型认为出现概率比较高的文字
我们还可以看到相同的话在后面出现了很多次,
这就是由于概率导致有可能触发的重复句子的问题
我们简单总结一下,GPT 就是通过海量的文本、数据训练后,拥有了“预测”下一个字可能是什么的能力,通过不断的预测,它就可以一直根据前面的文本续写文字。
当然在这背后还有海量的技术问题被省略, 但我想不断预测或者说续写就是 GPT 和其他大语言模型最核心的一点
现在我们大概知道,为什么 GPT 能写一堆看起来没有问题的话了吧,哪怕实际内容非常错误,但咋一看还挺有道理的, 因为他的原理就是基于概率的预测, 而它输出自以为正确但实际时编造的东西, 这一现象被称为幻觉, 可以通过引入外部资料的技术缓解(比如 RAG 技术等)
虽然 GPT 使用虽然能给我们带来很多帮助, 但对于生成的内容也要多加小心仔细验证哦,正如 ChatGPT 官网下写的那句ChatGPT 可能生成错误信息,需要确认
另外相信大家对 GPT 为什么能生成这么自然的话语也有一定的了解了, 总之就是不断的 "预测"!