之前介绍的预训练 + SFT,虽然已经能让 LLM 完成大部分工作,但在后训练阶段我们还能继续增强它,因此引入 强化学习(RL), 简单来说,RL 给模型提供了另一种**“自我探索与优化”**的能力
我们先回顾 SFT:是“人类先写好理想回答”,模型去模仿。但也许人类自己也不知道最优解, 或者写不出最适合模型“内部思维”的过程。LLM 的拥有的知识比单个人类多得多, 所以在解释复杂概念和解决问题时,人类标注员可能不清楚应该提供多少中间步骤。太详细可能增加 token 消耗;太简略又可能使模型无法进行充分推理。由于 LLM 的内部难以被理解,最优的"思考步骤"粒度很难由人类预先确定
而 RL 做法就是先给出问题让模型自己尝试回答,再根据正确与否的反馈(有固定答案的,比如数学,编程等可以自动验证, 没有的可以让人类或者奖励模型评分),然后收集“好回答”的样本来再次训练调整模型的参数,从而出现一些“超越人类示例”的方法或思路
可验证场景下的 RL
如果问题有明确的正确答案,例如数学题或编程任务,我们就可以完全自动化打分。流程类似:
- 给定同一个问题,模型多次生成不同回答。
- 哪些回答是正确的,就标记为成功;错误的标记为失败。
- 下一步训练就更强化那些成功样本的概率,使模型学会它自己的“最佳思路”。
这些思路并不一定跟人类写的解题方式一致,可能更适合模型内部的推理流程。有时模型还能发现人类没想到的巧妙招数,就像 AlphaGo 在围棋对弈里发现了“招法 37”那样。这就是 RL 强大的地方。
训练时会同时进行成千上万不同的问题和回答来不断迭代模型, 让模型逐渐找到什么样的 token 序列能让它正确回答问题

比如代码,或者数学,物理问题等,答案是可以验证是否正确的
通过验证答案后哪些符合要求的就会被作为示例, 再次用于训练 LLM
不可验证场景:人类反馈强化学习(RLHF)
如果题目没法自动判定好坏(比如“写一首关于鸭子的诗,看哪个更好”),我们不能直接程序判对错,就需要人类评分来监督
但如果用极大量的数据一直让人评分,那成本非常高。于是出现了 “RLHF”(Reinforcement Learning from Human Feedback)技术。它主要思路是:
- 人类仅对少量候选回答做排序,得到哪个更好或更差。
- 用这些有限的对比数据,去训练一个 “奖励模型”(reward model),让它学会模拟人类的好恶。
- 然后在大规模 RL 的时候,用这个奖励模型给出评分,用来指导模型强化学习。这样就不必让真人审阅海量输出。
不过 RLHF 也有难点:奖励模型并非完美,RL 过程可能产生“对奖励模型的投机取巧”,出现各种“对人类其实并不好的回答,但在奖励模型眼里分数很高”的情况。如果继续强化下去,就容易过拟合到奖励模型的漏洞里,导致输出怪异。这时往往要提前截断或改进奖励模型。总之,RLHF 带来一定收益,但也有局限。
像我们在使用 ChatGPT 时,对于不满意的答案重试再继续, 点赞, 出现两个答案时的选择等,都可以在以后模型的训练里提升它们的质量
DeepSeekR1 的奖励模型准确性奖励:准确性奖励模型评估响应是否正确。例如,对于有确定结果的数学问题,要求模型以指定格式(如在方框内)提供最终答案,使得可以可靠地通过基于规则的验证来检查正确性。类似地,对于 LeetCode 问题,可以使用编译器根据预定义的测试用例生成反馈格式奖励:除了准确性奖励模型外,我们还采用格式奖励模型,强制模型将思考过程放在'
'和' '标签之间
整体总结
综上所述,大型语言模型(LLM)一般经过以下大致流程:
- 预训练(Pre-training):把整个互联网文本拿来训练,让模型学习最底层的大规模语言知识和常识,得到一个“基座模型”
- 监督微调(SFT):收集人工标注的对话数据,让模型学会“角色化”的问答、对话风格
- 强化学习(RL/RLHF):在可验证或带人类反馈的任务上,让模型反复尝试、不断改进,进一步提升“推理质量”或“与人类期望一致度” (推理模型大量进行这一阶段)
类比一下我们学习知识的话, 预训练就是老师讲解给我们各种新知识, 而 SFT 就是我们通过看解题过程来学习怎么解题, 而强化学习就像是我们自己去做题并从错误中学习
目前第一 二步已经相当成熟,各个厂商做法都类似;第三步仍在快速探索和演进中。而 ChatGPT, 不仅用了上面这些,还叠加了更多工程细节,比如调用搜索、代码解释器、长上下文处理、合规审查等
第三步经常是各个厂商自己内部尝试, 很少公开讨论 (毕竟都花了很多钱来试验), 但 DeepSeek 的开源论文就公开了不少他们的尝试细节
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via...
比如 R1 就在 RL 训练阶段时,自己不断加长输出,并且思考和反思来提升准确率 ,这并不是在人工标注的示例给出的, 但也有对于简单的问题长度也过于长的问题,相信很多人在使用 DS 时都遇到一个很简单的问题,他要推理很多后才能给出一个简单的结果
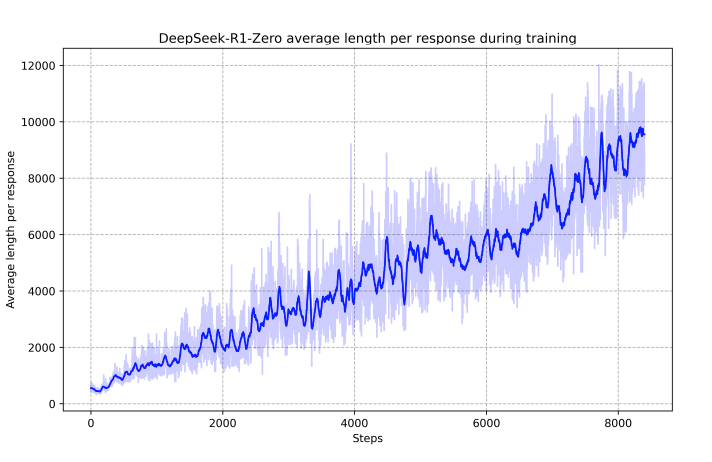
随着 RL 训练进行,R1模型的回复长度越来越长,准确率也提高了
DS 创新性的训练方法(RL优先)
- DeepSeek-R1尝试了纯粹依靠强化学习(RL)训练模型,没有先进行监督微调(SFT)
- RL阶段使得模型自主地探索出更长、更复杂、更清晰的“思考链”(Chain-of-thought),具有“自我验证”和“反思”等高级推理行为
- 这种纯RL方式培养出了很强的推理能力,但也存在冗长重复的问题
- 因此,后续引入了少量 SFT,再配合两轮强化学习,使得模型在具备基础语言能力基础上,显著提升推理准确度和表现
这种训练方式最特别之处在于:
- 依靠极少量的人类标注数据
- 大量使用奖励信号和模型自身探索,达到与OpenAI最高端模型(o1)相当的推理表现
另外我们以上介绍的只是基本的概念,还有类似混合专家架构(Mixture-of-Experts,MoE), Constitutional AI, DPO 等技术让我们最终用到现在最先进的这些 LLM 模型
未来发展
- 多模态(multimodal):模型不仅能处理文本,也能处理图像、音频、视频等。它们会把这些数据同样分词成 token,并在 Transformer 中混合处理 (例如 Gemini 2.0 Flash exp)
- 长任务/多步 Agent:模型将不仅仅回答单个问题,还能自己规划、执行更长流程(有的叫 Auto-GPT 之类)。但这对模型的记忆和自我纠错要求更高,还在早期 (如 Deep Research)
- 更广泛地嵌入到各种软件和硬件,从搜索、办公,到机器人、自动驾驶,都可能使用 LLMs 作为核心算法之一
- 新的训练方法:比如引入更多交互式学习、在线训练、动态更新等,试图让模型像人类一样在使用中持续学习,而不仅仅是在训练阶段一次定型
最后, 这些模型虽然强大,却并非绝对可靠。在事实性问题上,建议多核查(就像 ChatGPT 下面一直写的"ChatGPT can make mistakes. Check important info."),因为它可能产生幻觉, 处理复杂推理或算术,最好让模型“分步解释”或“使用代码/计算工具”。模型并不真正“明白”或“意识”,它只是根据大量样本学到的概率分布;它能做很多近似推理,但也会在意料之外的地方犯“低级”错误
理想的心态是:把它当成“高级文字处理与推理工具”,能提升效率,但别盲目相信
随着时间推进,模型会越来越多样化、能力越来越强,也会在专业领域更快产生价值——但它们的缺陷和挑战也同时存在