概述
GPT是一种自然语言生成技术,它本质上的目标是以类似人类的文字续写出流畅的文字
而且在续写时它并没有一个整体的规划,而是一个字一个字生成的
这些生成的字的依据(概率)来自于训练它的无数的网络、书籍上的文字等
之所以每次一样的提问不会获得重复的回答是因为有随机的因素而不是只按最高概率出现的文字来继续(这样很容易造成重复)
而ChatGPT算是GPT的微调版本,让这种续写看起来像机器和人在“对话”
开篇的题外话
这可以看出中文互联网的封闭(比如各种搜索引擎找不到的app内的内容)和审查以及无数广告等垃圾内容让中文的AI训练变得十分困难,
根据OpenAI官方的GPT3训练数据统计,中文训练资料(按照词排序)只能排到第17位,占比0.099%,但中国的人口却占了世界的18%.所以我国想要发展出自己的对话AI的话不仅训练需要的硬件(比如显卡等)受到限制,语料同样也会受到限制
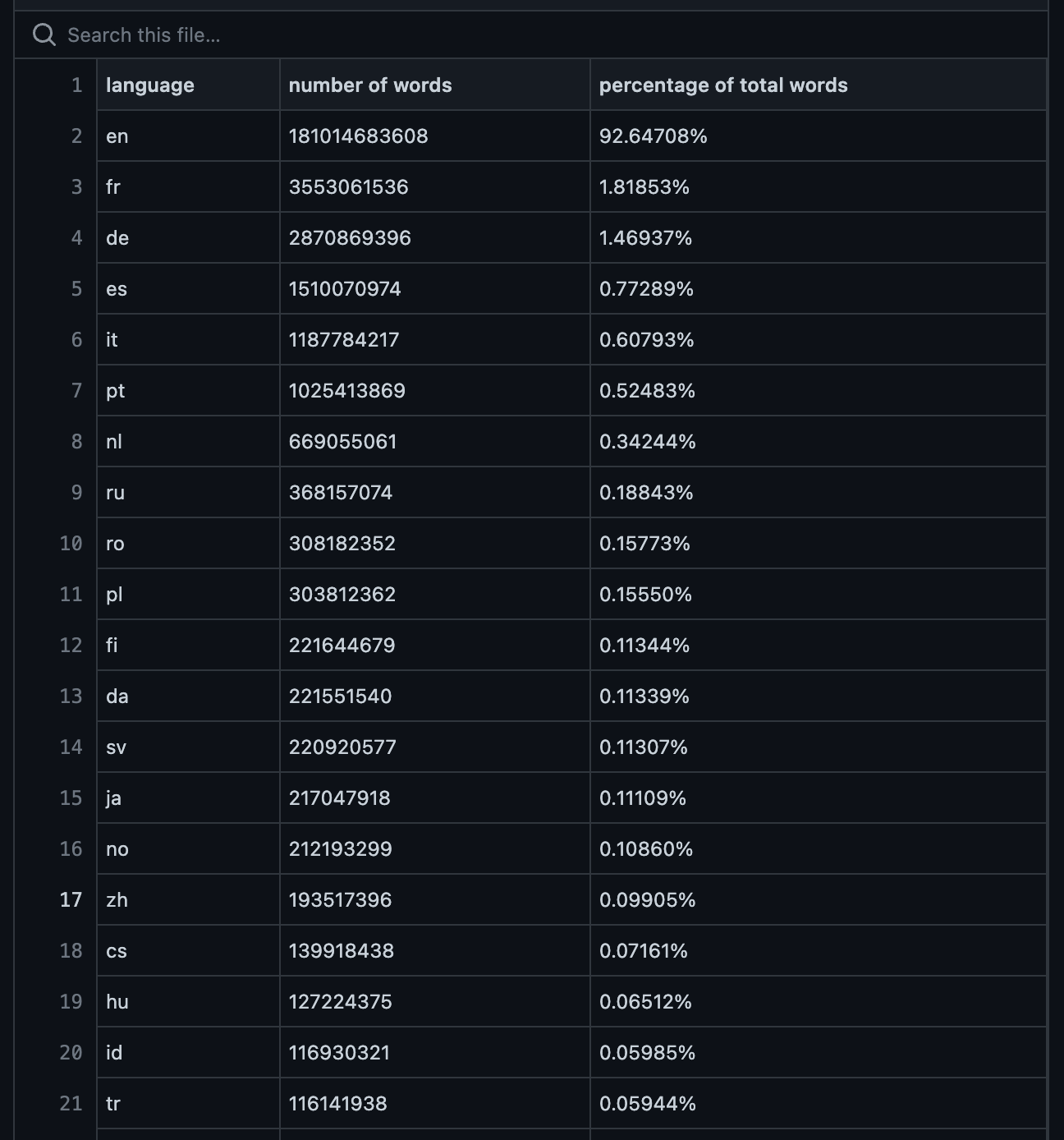 (GPT3的训练数据不同语言词数统计)
实际在使用ChatGPT时英语的输出体验也确实要比中文流畅、自然很多
那为什么就算中文训练数据这么少,依然也能输出还可以的中文内容呢.
其实它可以融会贯通各种语言,相当于可以把其他语言的知识“翻译”成中文,这也是为什么有人会觉得中文比较生硬的原因.
(GPT3的训练数据不同语言词数统计)
实际在使用ChatGPT时英语的输出体验也确实要比中文流畅、自然很多
那为什么就算中文训练数据这么少,依然也能输出还可以的中文内容呢.
其实它可以融会贯通各种语言,相当于可以把其他语言的知识“翻译”成中文,这也是为什么有人会觉得中文比较生硬的原因.
预测文字
继续说回字的生成,也就说它在生成每一个字的时候,其实是在根据前面的那些文字决定下一个词最有可能是什么(根据出现的概率等)、最好.
当然如果只按照下一个词出现的最高概率来生成的话,结果并不会很理想,除了死板外还容易自我重复等等,所以实际上GPT会随机地选择概率比较高的词来续写.所以每次的结果都不太一样.
比如下面这个OpenAI官方的GPT3续写的例子
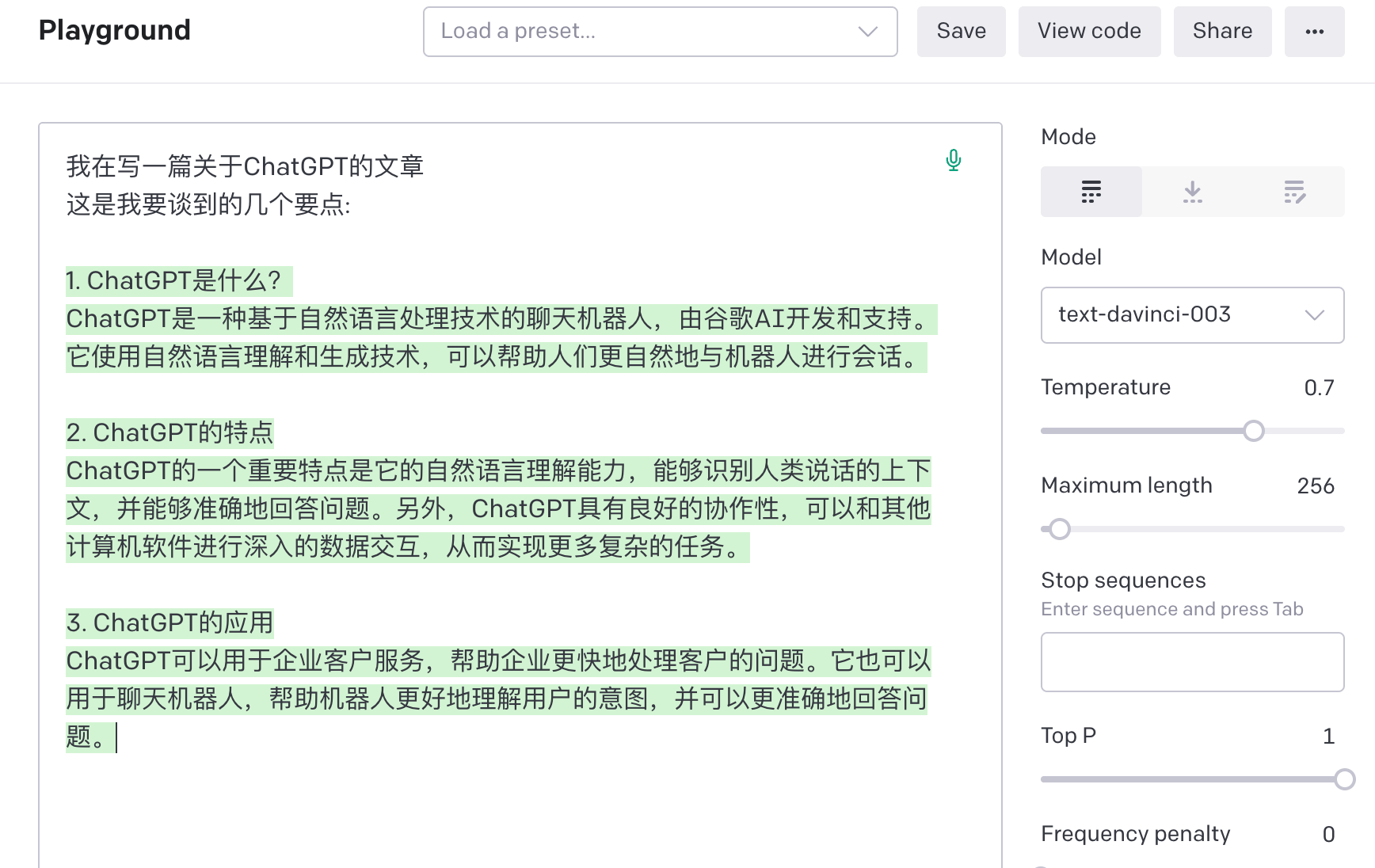
(使用GPT3续写文字的例子)
我先写了一段话(黑色部分),然后由AI预测我后面将会写什么(绿色覆盖的部分),当然由于他的训练数据截止到2021年,所以它其实并不知道ChatGPT是哪家公司开发的,而只是根据“GPT”推断它是一个理解自然语言的聊天机器人.
如果没有这种随机性的话,比如我给出“天空是”可能只会接上“蓝色的”,而不会考虑“多云”、“灰蒙蒙”之类的词,导致生成的内容可能不断在重复天空是蓝色的这个概念
(未完待续)
参考
这篇文章其实主要就是对Stephen Wolfram的讲解做个读后感,大部分图片和内容都来自于他, 然后加上了我自己的理解
Stephen Wolfram 讲解的 What is ChatGPT doing...and why does it work?