什么是预训练
GPT 中的 Generative Pre-trained Transformer 的 Pre-trained 就是指的这一步
在我们收集到了各种互联网和各种数据后并把它们都转换为 tokens 后,就到了 LLM 训练最核心的 预训练 步骤:我们要训练神经网络去 “预测下一个 token”。具体做法是在数据里随机抽取一段文本然后让模型去预测下一个 token:
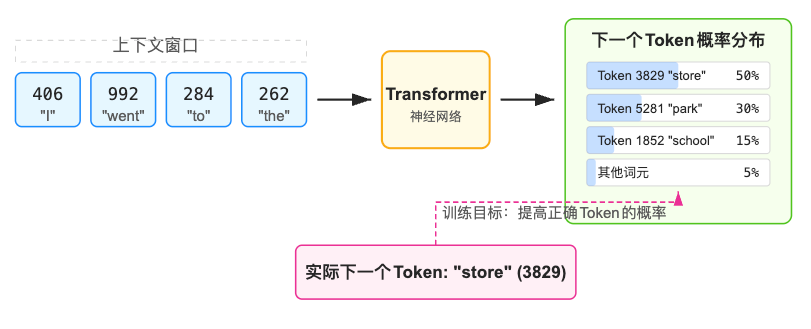
如果截取的 context window 是 ”I went to the park” , 那么模型可能给出不同几率的 store, park, school, 那么就会调整模型参数/权重以让 park 被预测的概率提升, 过程中会这样并行的对整个数据集进行这样的训练⬇️
- 从超大文本里随机取一段长度不定的 token 序列(称作 context window)
- 给模型输入这段序列(比如 context window 前面四五千个 token)
- 模型输出一个在词表大小范围内的概率分布,表示“下一个 token 会是哪个”
- 我们知道真实的“下一个 token”是哪个,因此可以计算误差。然后我们通过反向传播来微调模型参数,使模型逐渐把正确 token 的概率调高
- 不断重复在海量的数据上迭代更新,直到模型对“预测下一个 token”这件事上做得越来越好
从一开始模型的参数是随机的,预测也是乱猜 甚至不能生成完整的单词;但经过足够多轮训练后,模型就逐渐能捕捉到“文本序列中各种语言模式与统计规律”。比如它会学到语法结构、语义关联、常识知识等——只要这些信息对预测下一个 token 有帮助,都可能被学会。
神经网络内部:Transformer
本质上,Transformer 是一个巨大但确定的函数,它接收一段 token 序列(最多可到上万甚至十几万 token),内部做一堆矩阵运算、自注意力机制、MLP 层等,最终输出对每个位置接下来可能 token 的概率分布。训练的目标就是不断修改这些“网络参数”,让它越来越善于预测
内部原理虽然数学上可以展平成“无数个加减乘除、激活函数等运算”,但从高层看,你可以把它想象成一张超大计算图,每一层都有若干注意力头、多层感知机等,向后一直堆几十层甚至上百层,最后输出所有 token 的下一个 token 概率
推理(Inference)
训练完成后,就可以用这个模型进行“推理”了。(注意和o1,R1 之类的推理模型的推理不是一个意思),其实就是在给定一段“上下文(context)”后,模型不断抽样生成下一个 token;再把这个 token 拼回上下文,继续让模型生成下一个……周而复始,最后得到一大串文本输出
因为每次都会根据概率分布进行抽样,所以输出是 随机 的,可能每次生成的内容略有不同。一般我们会对这个概率分布做一些**采样或温度调控,让文本更有创造性或更贴近事实。**模型训练完成后,模型的参数就不会改变了, 所以推理过程不会改变它的参数
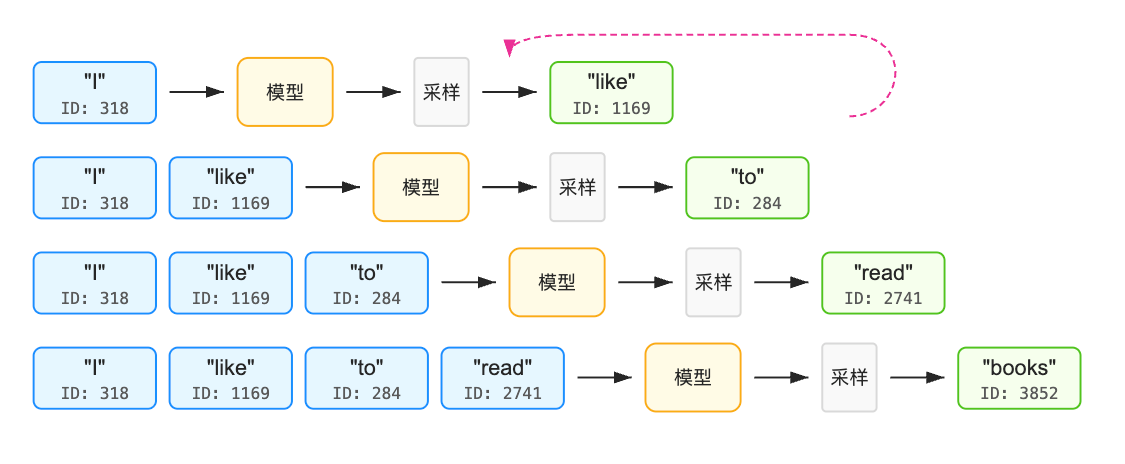
采样就是从这个概率分布中选择一个具体token的过程。有几种常见的采样方法:
- 贪婪采样:总是选择概率最高的token
- 温度采样:通过调整"温度"参数控制随机性的程度 (我们经常能在调用 API 时看到温度值这个选项就是说的它)
- Top-K采样:只从概率最高的K个选项中随机选择一个
- Top-p采样:选择概率总和达到阈值p的最小集合中随机选择一个
如果好奇过程是怎么样的可以看看这个可视化网站 LLM Visualization

文本被 LLM 一个一个 token 按照概率生成
基座模型(Base Model)
如果我们把上面的预训练流程跑到最后,就可以得到一个所谓 基座模型(Base Model)。这个模型只做了“预测下一个 token”这件事,并没有经过任务定制,也没有特别针对对话进行调教。
- 它读了海量互联网文本,所以知识面很广,但也只是以概率方式学到常见的语言模式。
- 它不会自然地根据人类提问来回答,更可能是“自动补全文本”的风格,相当于一个“互联网页面片段模拟器”。给它任何提示,它就朝着“最像什么互联网文本”那个方向去续写。
这种基座模型有时也能做简单对话,但往往不稳定,而且没有对话中那种“有礼貌、有上下文”的特性。举例来说,如果你直接问“2+2 等于多少?”,预训练模型可能并不一定回答“4”,也可能乱扯到别的地方, 比如给你 3+3 4+4 这样的续写。因为它只是根据统计学发散生成。
另外基座模型一般不会开放使用,它更像是"互联网文本模拟器”, 你给出一段文本它接着续写这段文本在互联网上接着是什么
这个阶段是训练一个模型成本最大的时候,并且这是模型知识的来源
在实践中,厂商通常会在预训练后进行一个或多个后续步骤,把这“基座模型”打磨成一个更好用的“对话助手(assistant)”。这就需要我们之后介绍的第二大阶段——后训练(post-training)
Base Model 训练成本占比:大约 70%-85%,主要由计算资源驱动。 Post-training 成本占比:大约 15%-30%,包括计算成本和数据/人力成本
我们可以将 Base Model 当成成一个受过良好通识教育的人,具备广泛的知识储备和沟通能力,但在特定行业(例如医疗、金融、编程)可能缺乏专业知识。当你需要一个在特定领域表现优异的模型时,就需要在 Base Model 基础上进行特定任务的微调, 比如最开始的 Github Copilot 就是基座模型加上额外的代码训练然后做到了代码补全的